
글또 두 번째 포스팅은 DEVIEW 2019라는 세미나에서 Operational AI 내용을 정리하였습니다.
지속적으로 학습하는 Anomaly Detection 시스템이라는 주제가 흥미로워서 듣고 정리하였습니다.
해당 발표는 Makina Rocks의 김기현 님이 발표하셨습니다.
제조업에서의 AI
배경
- 반도체 공장의 기계는 비쌈
- IoT의 발달로 많은 데이터 생성
- 딥 러닝의 발달로 큰 모델 생성 가능
제조업에서의 AI 도입을 통해 수익률 및 원가 절감 기대
현실에서 Digital Manufacturing Solution을 도입하려는 대부분의 기업은 아직 파일럿 Page에 머무름
파일럿 Page에 머물러 있는 이유가 무엇일까?
- 사례의 부족으로 문제 정의의 어려움이 있음
- 선행 비용 발생으로 인한 리스크 증가
- 데이터 수집을 위한 센서 설치 및 과제 발주
- 레이블 불균형 문제
- 수집 데이터는 대부 부분 정상 데이터이기 때문에 학습이 어려움
- 비정상 데이터가 학습에 기여하는 부분이 작아 학습이 어려움
- 비정상 특징을 배우기에는 데이터가 부족함
- 지속적인 제조 공정의 변화
- 한 번의 모델 학습으로는 계속되는 공정환경 변화에 대응할 수 없음
- 새로운 부품을 찍어내는 머신
- 기계 장비의 노후화
- 위의 문제로 인한 데이터의 입력 분포 변화로 인해 공정 변화에 대해 대응 불가
- 한 번의 모델 학습으로는 계속되는 공정환경 변화에 대응할 수 없음
제조업 AI를 적용하기 위한 어려움과 해결방안(Feat. 로봇팔)

현대 생산 공정에서 산업용 로봇 팔의 역할
- 인건비 증가로 인한 산업용 로봇의 수요 증가
- 위험하고 어려운 작업, 지치거나 실수하지 않음
- 연도별 산업용 로봇의 보급이 큰 증가 추세를 보임
고장 시점을 미리 예측할 수 있다면?
- 예상치 못한 가동 중지로 인한 손실 발생을 최소화 가능
- Ai의 고장 징후 탐지
- 필드의 엔지니어는 미리 부품 준비
- 즉시 부품 교체
- 다운 타임 감소 및 비용 절감, 생산성 향상
Anomaly Detection (Reconstrtuction along Projection Pathway(RaPP)
이진 분류?
- 정상 데이터와 비정상 데이터 분류
- 디시전 바운더리를 찾는 과정
- 하지만 클래스 Imbalance 문제와 Open World 분류 문제에 직면
Novelty detction?
- 정상 데이터만을 학습한 후 비정상 데이터를 걸러내는 알고리즘
- 비정상 데이터 확보 어려움, 일반적인 분류 모델 적용 불가
- 정상 데이터의 특징을 학습
- 학습 과정에서 관찰되지 않은 특징이 나타나는 경우 탐지
기존 방법
- 정상 데이터의 범위 정의를 통해 비정상 샘플 탐지
- 차원 축소를 통한 특징 추출- PCA
- 클러스터링을 통한 확률 분포 근사 - GMM
딥 러닝 기반의 방법

- 오토 인코더 방법
학습 : 특징 추출을 통한 학습
장점 : 비선형적인 차원 축소 기능을 제공, 학습이 용이
단점 : MSE 손실 함수 사용으로 인해 복원 성능이 떨어짐
- GAN기반의 방법
학습 : 적대적 학습을 통한 생성기와 판별기 훈련 후에 픽스된 생성기에 인코더를 붙임
장점 : MSE 손실 함수에 비해 복원 성능이 좋음
단점 : 차원 축소 X, 학습이 불안정함
Motivation of RaPP
인코더와 디코더의 중간 결과물을 활용하여 성능 향상 가능?
- 결과적으로는 어렵다.
- 양 끝단의 차이를 최소화하기 때문에 중간단은 의미 없음

RaPP
- 복원 샘플을 다시 인코더에 넣음으로써 문제 해결
- 앞서 말한 인코더와 디코더의 중간 결과물을 활용 가능

RaPP - Intuition
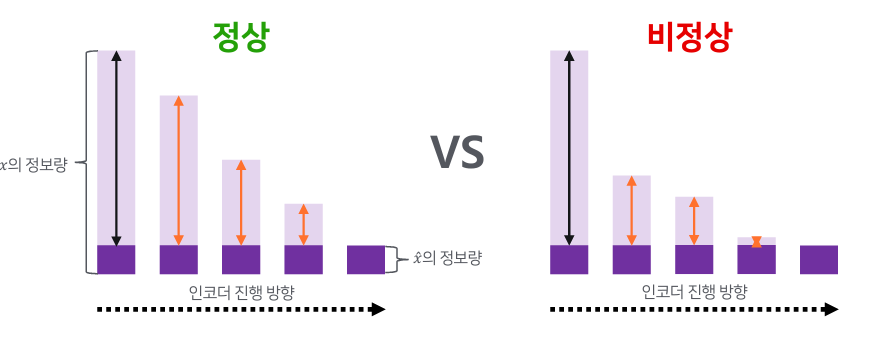
- 일반적인 AE의 경우 비정상 샘플의 경우에도 복원이 잘되는 경우가 생김
- 하지만 RaPP는 중간 딴의 결과도 사용함에 따라 높은 Novelty Detection 성능을 얻을 수 있었음
NormalizedAggregation
- Novelty Detection을 수행을 하기 위해서는 각각의 샘플에서 Anomaly Score가 산출되어야 함
- 각 Layer 별로 점수가 산정되기 때문에 합치는 과정이 필요
- 단순히 더하는 과정을 진행 시 각각의 점수의 Scale 이 다르기 때문에 불가능
- 따라서 SVD 통해 서로 다른 Reconstruction Error을 정규화해야 함

Evaluation Metric
- 각각의 테스트 샘플에서 결과의 분포를 찍어 보았을 때 정상과 비정상의 분포를 알 수 있었음
- 높은 성능의 Novelty Detection 모델이라고 한다면 두 분포가 멀리 있을수록 성능이 높다 할 수 있음
- 분포 사이의 임계값을 구하기 쉽기 때문임

Experiment Setup
- Multimodal/Unimodal normality case에 대해 실험을 수행
- Mnist 데이터를 통한 실험 수행
- Multimodal?
- 9개의 클래스를 정상으로 지정하여 학습한 후 나머지 하나를 테스트 과정에서 이상치로 지정
- Unimodal?
- 1개의 클래스를 정상으로 지정하여 학습한 후 나머지 9개의 클래스를 테스트 과정에서 이상치로 지정
- 결과적으로 기존 방식보다 더 다양한 이상 샘플을 정확하게 탐지
RaPP Result

- 기존의 모델과 같은 경우
- 1의 모양이 단순해서 학습 과정에서 보지 못했음에도 불구하고 다른 클래스의 정보를 통해 잘 복원한 모습을 보임
- RaPP와 같은 경우
- 1을 잘 탐지 못하는 기존 연구와는 반해 성능면에서 잘 탐지하는 모습을 보임
RaPP Evaluation
- 다양한 baseline과의 비교 실험을 통해 검증
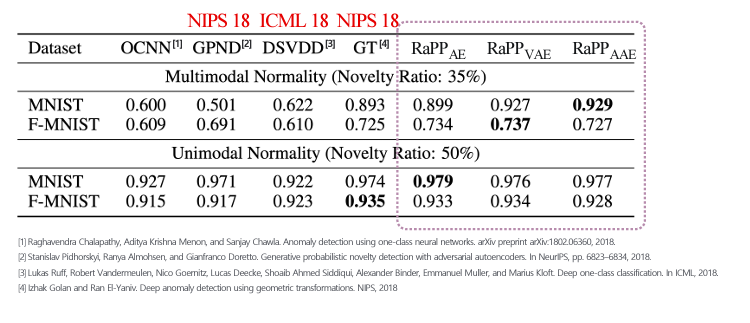
- Mnist와 같은 경우는 현실에서의 데이터와는 다른 양상의 데이터 이므로 캐글에 존재하는 센서 데이터를 통해 실험 진행

RaPP가 성능적으로 좋은 모습을 보이지만 실제 산업에서 사용되는 로봇팔의 이상에도 잘 작동할까?
영상으로 명확하게 보여주어 아래에 링크를 남깁니다.
(21분 30초쯤 가시면 볼 수 있습니다.)
https://tv.naver.com/v/11207334
Operational AI: 지속적으로 학습하는 Anomaly Detection 시스템 만들기
NAVER Engineering
tv.naver.com
이것으로 글또 두 번째 포스팅을 마치겠습니다.
뒤에 내용이 더 있는데 내용이 너무 많아 나머지 내용은 다음 주 주중에 정리할 예정입니다.

긴 글 읽어 주셔서 감사합니다.
'Review > Seminar' 카테고리의 다른 글
| DEVIEW 2019 : Operational AI 발표 정리(2) (0) | 2021.08.21 |
|---|